What GREMLIN provides¶
Any big facility — FAIR, FCC-scale, any large research or industrial site — runs thousands of distributed switching loads. Instrumenting and fault-monitoring each one individually is expensive, fragile, and gets in operations' way. GREMLIN's premise is that the right place to measure is the one place every load is already connected to: the shared mains feed.
As a diagnostic layer, it converts a single high-bandwidth measurement of the conducted EMI on a facility's mains feed into operational outputs along the two axes that matter most for any facility operations — the energy footprint (where the power actually goes) and availability (catching device degradation before becoming a hard fault).
GREMLIN's operational diagnostic mechanisms - see where the power goes, spot efficiency drift, catch faults early, plus secondary upsides - feed two axes: energy footprint and availability.
-
See where the power goes — disaggregated energy footprint The disaggregation chain returns a per-device estimate of power consumption derived from a single upstream measurement, exposing the long tail of non-essential loads that operations is typically blind to at facility level. Once those loads are visible by device class, by operating state, and by time of day, operations can act on them: shed what isn't needed, schedule what is. The sequence is deliberate — GREMLIN reports, operations decides and acts. The system is a diagnostic layer, not an energy controller.
-
Spot efficiency drifts in ageing converters Comparing each device's RF/EMI signature against its measured power consumption over time exposes power converters whose conversion efficiency is degrading silently. Recovering a few percent on a multi-megawatt-class load is, in order of magnitude, ~ 20 GWh per year at a facility the size of FAIR — the kind of number that pays back the rest of the diagnostic on its own, if the false-positive rate is low enough for operations to act on the alerts. That conditional is exactly what the iRIS benchmarking deliverable quantifies.
-
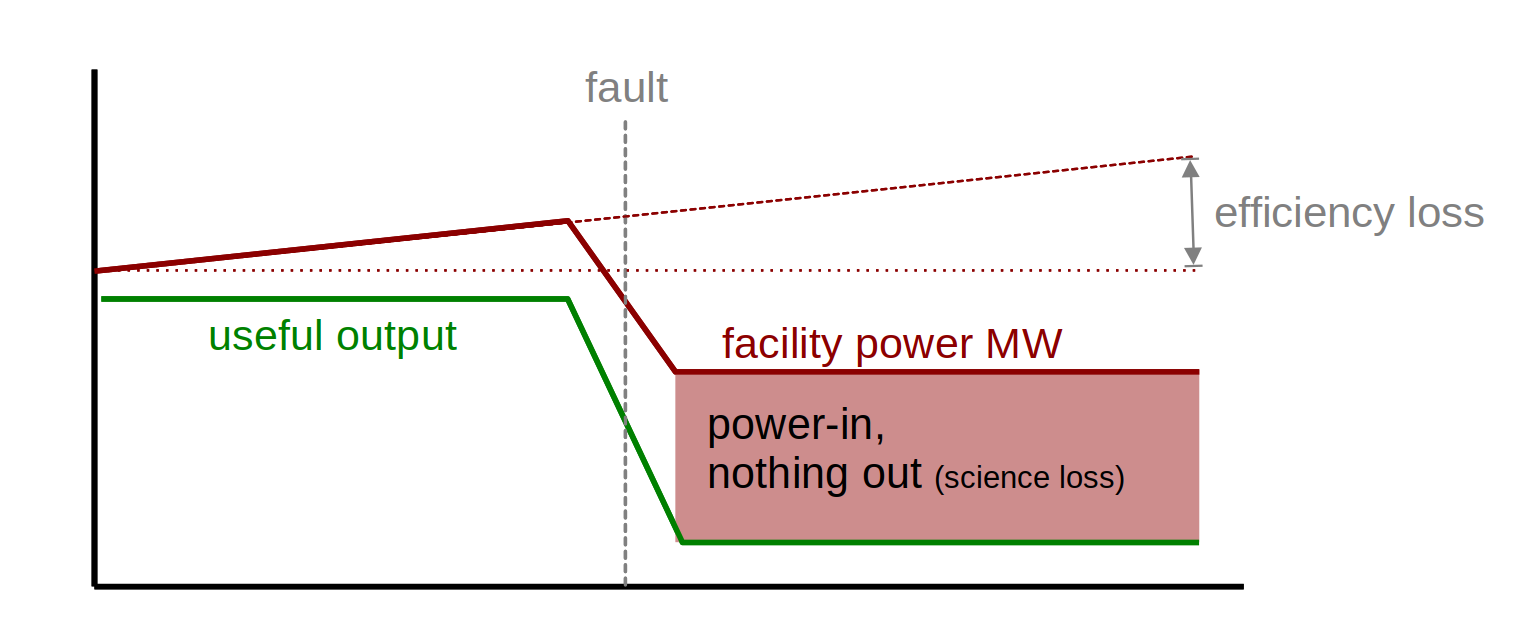
Catch faults before they are hard faults — availability The same single-point measurement supports early detection of device-level degradation, so maintenance can be proactive and grouped — scheduled into existing shutdowns, maintenance windows, and commissioning gaps — in place of reactive responses to single-point failures. The economic case is strongest in facilities that cannot be cycled rapidly: cryogenic plant, RF systems, thermal infrastructure, hysteresis-limited magnets. There, a hard fault means the place idles while still drawing megawatts, and the cost of lost beam time at GSI's SIS18 is on the order of 120 kEUR per day of lost science. Fault-prevention therefore pays on both axes at once — saved kEUR of lost science and avoided MWh burned during the idle window. The physical drift that makes this early-warning possible is summarised in Ageing as signature.
-
Further upsides — secondary outputs from the same spectral view The same single-sensor disaggregation supports several second-order benefits that do not require an additional measurement:
- Unaccounted-for loads and devices — the analysis flags power drawn on the network that does not match any known device signature. The disclosed fact is that something is consuming power matching no known fingerprint, not what it is doing internally. (Open scope of how this is used in practice is best discussed off-line.)
- Grid and emission-compliance monitoring — exceeding the network operator's emission or power-quality tolerances carries operational or contractual cost, and the same high-bandwidth spectral view supports staying inside them. GREMLIN rides on a problem the facility already owns.
- Avoided per-device metering — capital, calibration, and embodied carbon. Instrumenting every load individually multiplies cabling, calibration, network endpoints, embedded firmware, and the embodied-carbon footprint of all the added electronics. GREMLIN avoids that.
- Maintenance-logistics dividends — just-in-time spares, remote triage of which device is failing before sending a technician, and deferred replacement-capex follow from knowing which device is degrading well before it fails.
Where it applies — application domains¶
The primary near-term target is FAIR and FCC-scale research infrastructure, alongside other large research facilities, in which the RF, magnet, and cryogenic systems are simultaneously the dominant loads and the most reliability-critical, and in which device-level instrumentation is not viable at scale. The underlying approach is general: the same single-point conducted-EMI sensing applies to any facility with a large, switching-power-electronics-heavy device population on shared mains.
- Critical large-scale infrastructure — data centres, hospitals, water and sewage treatment, manufacturing plants, grid substations, rail and metro traction power, district heating, telecommunications hubs. These domains share the pattern of many switching loads on shared mains, with high opportunity-cost of unplanned downtime.
- Industrial sites with heavy power-electronics inventory benefit from the same disaggregation and signature-drift early-warning outputs.
Home and small-business deployments are not within the scope of the present project. The hardware and software are nevertheless released under free and open licence terms, and the project is open to engagement with industrial partners interested in adapting the approach to other application domains.
Honest Framing of Magnitudes and Maturity¶
Absolute MWh / € figures are an iRIS-GREMLIN deliverable
The four mechanisms in §§ 1–4 exist today. What iRIS funds is the industrial scale integration towards a TRL 6-7 and quantifying the savings they translate into at facility scale. The order-of-magnitude figures cited above — ~ 20 GWh per year for the efficiency-drift axis, ~ 120 kEUR per day of lost science at SIS18 for the fault-prevention axis — are the magnitudes of the inefficiency or loss-of-science cost that GREMLIN's outputs aim to address, not measured GREMLIN-attributable savings. The fraction of each magnitude GREMLIN actually captures is set by its detection performance (false-positive and false-negative rates) at the target device count, and that quantification is the work explicitly scoped under iRIS-GREMLIN Tasks III–IV.
Today GREMLIN is validated as an engineered model at small scale — under about twenty devices. iRIS funds maturing it to TRL 6–7 at fifty-plus devices, under real operating conditions.